
After months of anticipation, the leading AI technology is here! DT engineers have been testing out this incredible new hardware on its short stop at our lab before it’s sent to a top-secret customer. Our team has already seen some amazing results with the system for tackling complex workloads – and we can’t wait to see what lies ahead!
We dove head-first into the H100, diving deep to make sure it was up to task. After scoping out version compatibility and various drivers on offer, we gained a full understanding of its capabilities – read on to find out more.
To begin with we explored the system to check for version compatibility, drivers versions and outputs on capabilities.
# nvidia-smi;
[root@h100-8way mlperf]# nvidia-smi Sat Mar 11 11:17:15 2023 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA H100 80GB HBM3 On | 00000000:1B:00.0 Off | 0 | | N/A 64C P0 511W / 700W| 18420MiB / 81559MiB | 90% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA H100 80GB HBM3 On | 00000000:29:00.0 Off | 0 | | N/A 51C P0 575W / 700W| 18242MiB / 81559MiB | 88% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA H100 80GB HBM3 On | 00000000:45:00.0 Off | 0 | | N/A 51C P0 582W / 700W| 18174MiB / 81559MiB | 88% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA H100 80GB HBM3 On | 00000000:4E:00.0 Off | 0 | | N/A 65C P0 598W / 700W| 18334MiB / 81559MiB | 89% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA H100 80GB HBM3 On | 00000001:1B:00.0 Off | 0 | | N/A 65C P0 646W / 700W| 18278MiB / 81559MiB | 87% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA H100 80GB HBM3 On | 00000001:24:00.0 Off | 0 | | N/A 51C P0 551W / 700W| 18246MiB / 81559MiB | 89% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA H100 80GB HBM3 On | 00000001:45:00.0 Off | 0 | | N/A 51C P0 625W / 700W| 18210MiB / 81559MiB | 88% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA H100 80GB HBM3 On | 00000001:4E:00.0 Off | 0 | | N/A 63C P0 635W / 700W| 18290MiB / 81559MiB | 89% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 125827 C python 18326MiB | | 1 N/A N/A 125827 C python 18148MiB | | 2 N/A N/A 125827 C python 18080MiB | | 3 N/A N/A 125827 C python 18240MiB | | 4 N/A N/A 125827 C python 18184MiB | | 5 N/A N/A 125827 C python 18152MiB | | 6 N/A N/A 125827 C python 18116MiB | | 7 N/A N/A 125827 C python 18196MiB | +---------------------------------------------------------------------------------------+
Moving on to the CUDA supplied bandwidth test to check transfer speeds between GPUS and host.
# bandwidthTest [root@h100-8way demo_suite]# ./bandwidthTest [CUDA Bandwidth Test] - Starting... Running on... Device 0: NVIDIA H100 80GB HBM3 Quick Mode
Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 53774.7 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 53882.5 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 1943996.2 Result = PASS
The deviceQuery command is another useful tool for checking the attributes of the H100 card (we’ve snipped the output here as its quite lengthy for 8 cards!)
[root@h100-8way demo_suite]# ./deviceQuery ./deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 8 CUDA Capable device(s) Device 0: "NVIDIA H100 80GB HBM3" CUDA Driver Version / Runtime Version 12.1 / 12.1 CUDA Capability Major/Minor version number: 9.0 Total amount of global memory: 81090 MBytes (85028765696 bytes) MapSMtoCores for SM 9.0 is undefined. Default to use 128 Cores/SM MapSMtoCores for SM 9.0 is undefined. Default to use 128 Cores/SM (132) Multiprocessors, (128) CUDA Cores/MP: 16896 CUDA Cores GPU Max Clock rate: 1980 MHz (1.98 GHz) Memory Clock rate: 2619 Mhz Memory Bus Width: 5120-bit L2 Cache Size: 52428800 bytes Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 2048 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: 2147483647 bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 3 copy engine(s) Run time limit on kernels: No Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Enabled Device supports Unified Addressing (UVA): Yes Device supports Compute Preemption: Yes Supports Cooperative Kernel Launch: Yes Supports MultiDevice Co-op Kernel Launch: Yes Device PCI Domain ID / Bus ID / location ID: 0 / 27 / 0 Compute Mode: < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
</snip>
The end of deviceQuery confirms the all-to-all peering capability of the system
> Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU1) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU2) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU3) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU4) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU5) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU6) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU0) -> NVIDIA H100 80GB HBM3 (GPU7) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU0) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU2) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU3) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU4) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU5) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU6) : Yes > Peer access from NVIDIA H100 80GB HBM3 (GPU1) -> NVIDIA H100 80GB HBM3 (GPU7) : Yes ...
</snip>
Next, we check the busGrind tool, which provides detailed statistics about peer-to-peer memory bandwidth amongst GPUs present in the system as well as pinned, and unpinned memory bandwidth.
[root@h100-8way demo_suite]# ./busGrind Device: 0, NVIDIA H100 80GB HBM3, pciBusID: 1b, pciDeviceID: 0, pciDomainID:0 Device: 1, NVIDIA H100 80GB HBM3, pciBusID: 29, pciDeviceID: 0, pciDomainID:0 Device: 2, NVIDIA H100 80GB HBM3, pciBusID: 45, pciDeviceID: 0, pciDomainID:0 Device: 3, NVIDIA H100 80GB HBM3, pciBusID: 4e, pciDeviceID: 0, pciDomainID:0 Device: 4, NVIDIA H100 80GB HBM3, pciBusID: 1b, pciDeviceID: 0, pciDomainID:1 Device: 5, NVIDIA H100 80GB HBM3, pciBusID: 24, pciDeviceID: 0, pciDomainID:1 Device: 6, NVIDIA H100 80GB HBM3, pciBusID: 45, pciDeviceID: 0, pciDomainID:1 Device: 7, NVIDIA H100 80GB HBM3, pciBusID: 4e, pciDeviceID: 0, pciDomainID:1 P2P Cliques: Clique: 0 [0 1 2 3 4 5 6 7] ************************************************************************* ************************************************************************* Test Description: Bus bandwidth between the host and a single device ************************************************************************* Host/Device Bandwidth Matrix (GB/s), memory=Pinned Dir\D 0 1 2 3 4 5 6 7 D2H 54.99 54.95 55.18 55.18 55.17 55.17 55.18 55.14 H2D 55.08 55.21 55.27 55.31 55.26 55.25 55.28 55.29 BiDir 76.17 76.07 101.02 100.93 101.11 99.39 100.87 101.18 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth between the host and multiple devices concurrently ************************************************************************* Concurrent Host/Device Bandwidth Matrix (GB/s), memory=Pinned Dir\D 0 1 2 3 4 5 6 7 Total H2D 27.75 27.75 27.85 27.84 22.25 22.25 22.25 22.27 200.22 D2H 19.23 19.24 19.24 19.24 15.43 15.43 15.45 15.44 138.70 BiDir 27.92 27.93 26.98 26.98 23.23 23.11 23.15 23.06 202.35 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth between pairs of devices ************************************************************************* P2P Bandwidth Matrix (GB/s) - Unidirectional, P2P=Enabled D\D 0 1 2 3 4 5 6 7 01048.48 270.47 302.62 300.24 303.06 302.03 301.96 302.01 1 352.991180.58 357.02 356.55 353.91 353.99 355.28 355.19 2 354.13 357.081194.80 356.92 353.01 353.87 354.11 354.13 3 357.45 351.78 357.291162.14 355.07 354.79 355.28 354.61 4 354.69 354.83 354.53 355.921180.14 349.08 351.38 355.09 5 357.33 355.74 357.22 355.17 355.641194.80 352.41 354.67 6 357.78 352.99 358.41 352.13 351.26 350.791175.70 351.62 7 355.64 354.83 357.20 357.24 351.50 351.26 351.241179.91 P2P Bandwidth Matrix (GB/s) - Bidirectional, P2P=Enabled D\D 0 1 2 3 4 5 6 7 01310.00 709.42 703.12 710.95 706.77 703.00 703.12 705.78 1 706.531310.27 707.49 704.34 707.97 700.20 699.42 711.80 2 709.22 703.231308.49 704.38 707.13 700.36 704.27 709.22 3 699.30 713.19 707.891301.95 705.26 695.95 697.70 706.53 4 700.79 700.04 706.61 702.601302.49 696.61 700.20 705.02 5 704.98 706.21 707.69 713.92 710.191305.89 698.13 704.11 6 695.37 709.14 707.85 707.65 707.05 707.371302.35 706.45 7 706.61 711.04 710.15 702.41 705.14 698.01 702.481307.39 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth between pairs of devices running concurrently (assumes devices are paired in order) ************************************************************************* P2P Concurrent Exchange Bandwidth Matrix - P2P Enabled (GB/s) Dir\D 0<>1 2<>3 4<>5 6<>7 Total R2L 283.31 282.79 283.33 291.321140.75 L2R 374.01 372.62 372.22 376.761495.61 BiDir 747.79 747.88 747.25 752.152995.06 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth for a 1D exchange across devices running concurrently (assumes devices are ordered ideally) ************************************************************************* P2P Concurrent 1D Exchange Bandwidth Matrix - P2P Enabled (GB/s) Dir\D 0 1 2 3 4 5 6 7 Total R2L 296.42 315.78 307.05 311.44 310.10 311.16 280.38 0.002132.34 L2R 0.00 372.89 374.50 375.13 376.76 371.29 373.83 373.452617.84 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth for a cycle exchange across devices running concurrently (assumes devices are ordered ideally) ************************************************************************* P2P Concurrent 1D Exchange Bandwidth Matrix - P2P Enabled (GB/s) Dir\D H 0 1 2 3 4 5 6 7 H Total R2L 54.78 294.46 320.45 280.09 349.61 277.58 315.42 282.75 0.00 55.132230.28 L2R 55.20 0.00 376.71 377.28 372.02 370.28 374.90 369.63 354.21 55.112705.34 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus bandwidth for an all to all across all devices running concurrently ************************************************************************* P2P All to All Bandwidth Matrix - P2P Enabled (GB/s) Dir\D 0 1 2 3 4 5 6 7 Total Sctr 205.03 206.15 209.01 200.44 195.59 205.90 229.79 226.221678.13 Gthr 193.46 214.34 226.14 203.04 220.05 193.58 277.25 203.451731.32 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus latency between the host and a single device ************************************************************************* Host/Device Latency Matrix (us), memory=Pinned Dir\D 0 1 2 3 4 5 6 7 D2H 1.91 1.86 1.87 1.85 1.95 1.94 1.93 1.95 H2D 2.13 2.12 2.12 2.11 2.15 2.29 2.13 2.14 BiDir 3.04 3.05 3.06 3.03 3.14 3.19 3.21 3.15 ************************************************************************* ************************************************************************* ************************************************************************* ************************************************************************* Test Description: Bus latency between pairs of GPUs ************************************************************************* P2P Latency Matrix - P2P=Enabled (us) D\D 0 1 2 3 4 5 6 7 0 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 1 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 2 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 3 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 4 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 5 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 6 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 7 0.02 0.02 0.02 0.02 0.02 0.02 0.02 0.02 ************************************************************************* *************************************************************************
Next is the NCCL Test (which tests collective communications between the GPUs)
# yes yes I know its bad practise to run as root.. [root@h100-8way nccl-tests]# mpirun --allow-run-as-root -np 8 ./build/alltoall_perf # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # Rank 0 Group 0 Pid 384590 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384587 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384588 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384586 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384584 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384585 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384591 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # Rank 0 Group 0 Pid 384589 on h100-8way device 0 [0x1b] NVIDIA H100 80GB HBM3 # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 38.80 864.90 0.00 0 8.74 3837.40 0.00 N/A 33554432 8388608 float none -1 39.07 858.79 0.00 0 9.09 3692.29 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 38.67 867.79 0.00 0 8.05 4167.01 0.00 N/A # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # 33554432 8388608 float none -1 38.67 867.80 0.00 0 7.38 4546.98 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 39.36 852.40 0.00 0 7.77 4320.07 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 38.85 863.64 0.00 0 8.67 3871.52 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 39.27 854.47 0.00 0 8.51 3941.46 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 # # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 33554432 8388608 float none -1 39.34 852.85 0.00 0 7.64 4393.29 0.00 N/A # Out of bounds values : 0 OK # Avg bus bandwidth : 0 #
OK that’s enough synthetic work – let’s take a quick look at MLPerf (specifically th resnet50 training tests). TL;DR get your batch sizing right!
MLPerf benchmarking: one of the problems with such new hardware is that the NGC registry is not fully up to date on the H100 support. As a result, we had to rebuild the mlperf containers using the mxnet:23.02-py3 builds. The resulting Testing had mixed precision on the imagenet2012 dataset.
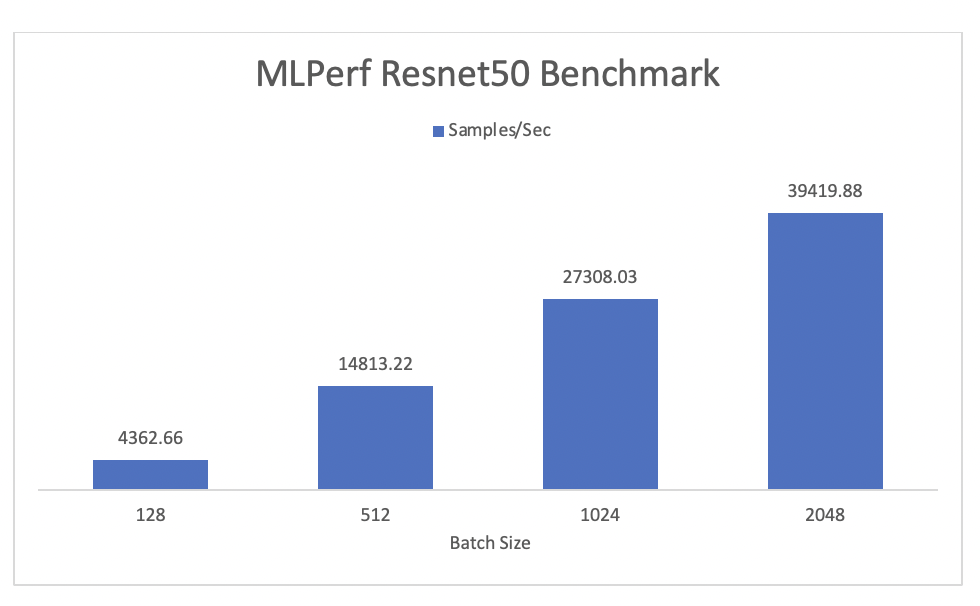
Unfortunately, our timeline didn’t allow us to complete all the tests we would have liked. But don’t worry – stay tuned for more updates and benchmarking results from our upcoming deployment! Plus, if you’re looking for a specific GPU setup then make sure to reach out and chat with the team about it.